
Mistarمسطار
Mistar addresses a common problem with scanned arabic books: they look readable, but they are not truly usable. Most arabic scanned PDFs behave like images, making text selection, editing, search, font control, and reformatting nearly impossible. Mistar solves this by converting scanned Arabic books into structured digital documents using layout detection, OCR, and AI-assisted text correction, then giving users review tools to refine and export the final result into accessible reading form
Tech Stack
AI-assisted digitization for scanned Arabic books
Key Features
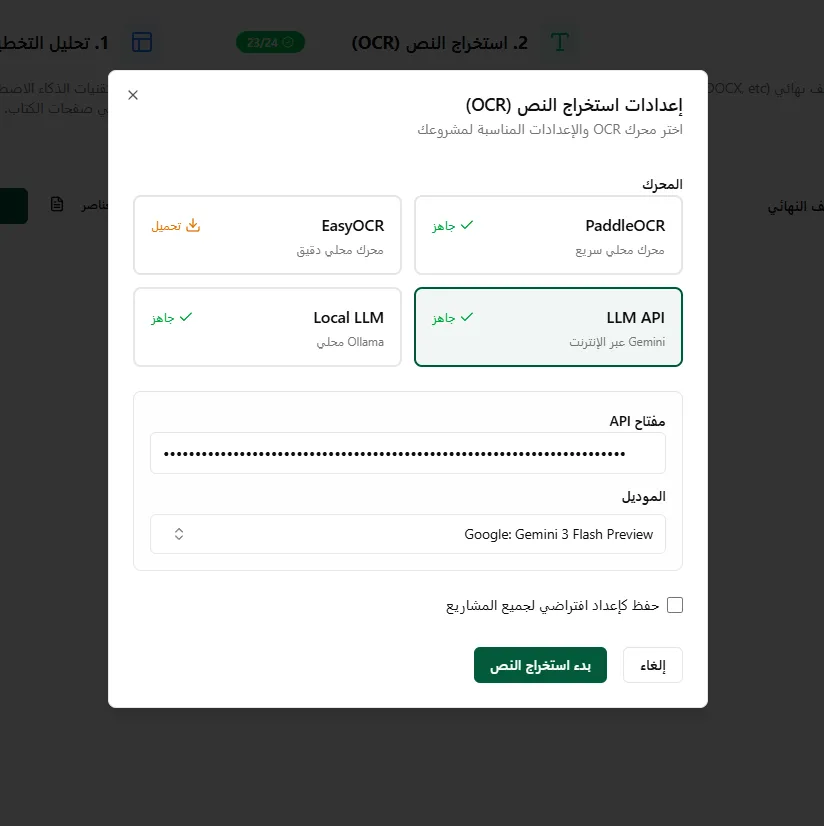
AI-Powered OCR for Entire Books
Mistar allows users to click a button to perform OCR on a fully scanned book using advanced AI techniques or through Paddle and EasyOCR, or local LLM models, all available for free (except cloud-based AI which will be costly but better).
Export to global book format Epub
Books can be extracted in different formats such as: - EPUB - MARKDOWN - JSON You can also choose the placement of images and various files, either in Base64 format or as separate files placed elsewhere.
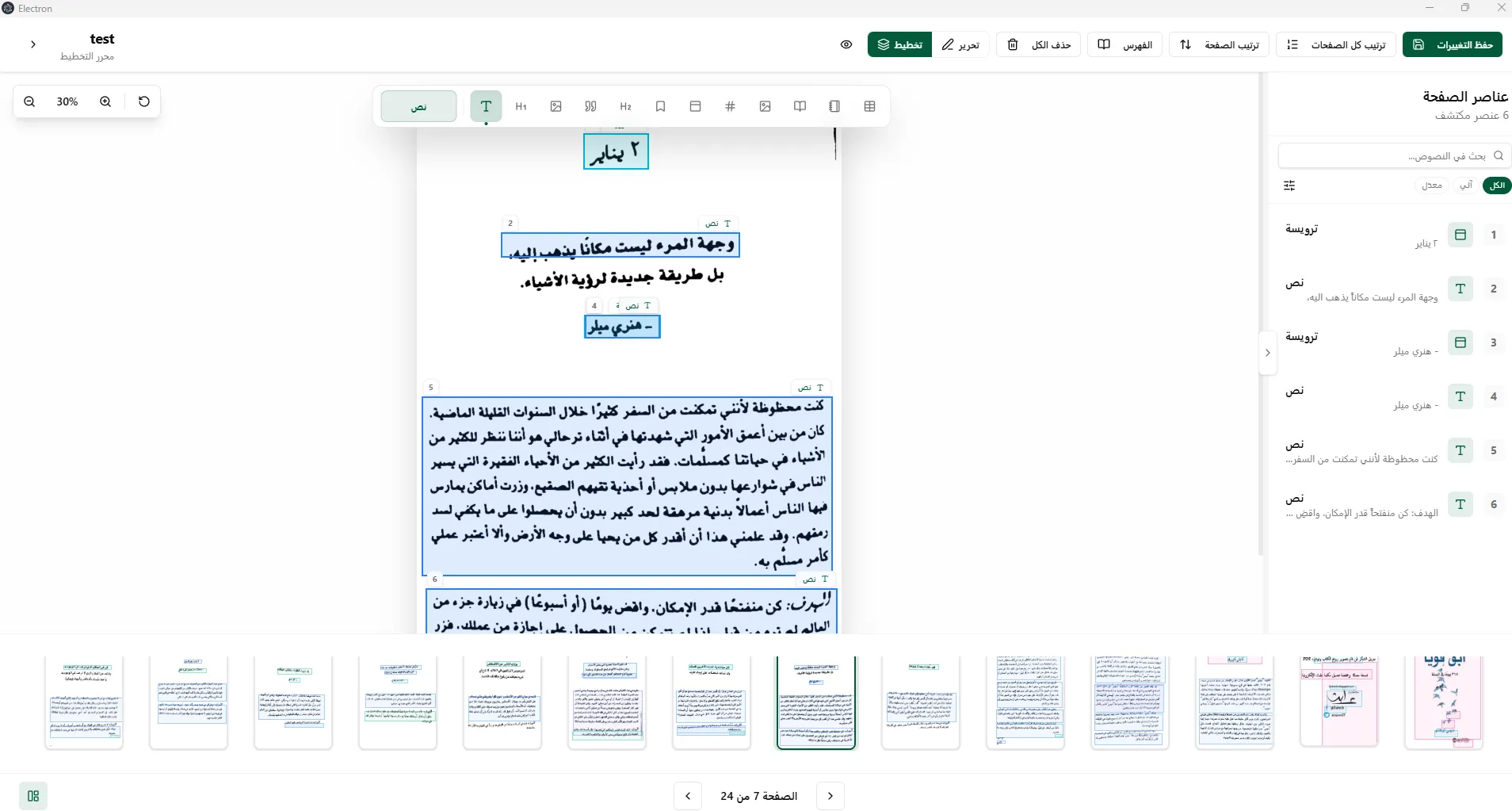
Adding and Detecting Layouts in Books
Easily add books for translation or OCR with our platform. The system automatically detects layouts using YOLO technology, ensuring accurate and efficient processing of your documents.
Extracting Text Using PaddleOCR (Accuracy Not Guaranteed)
PaddleOCR allows for offline OCR capabilities, providing flexibility for local use; however, it is not recommended due to potential limitations in performance and accuracy compared to online processing.
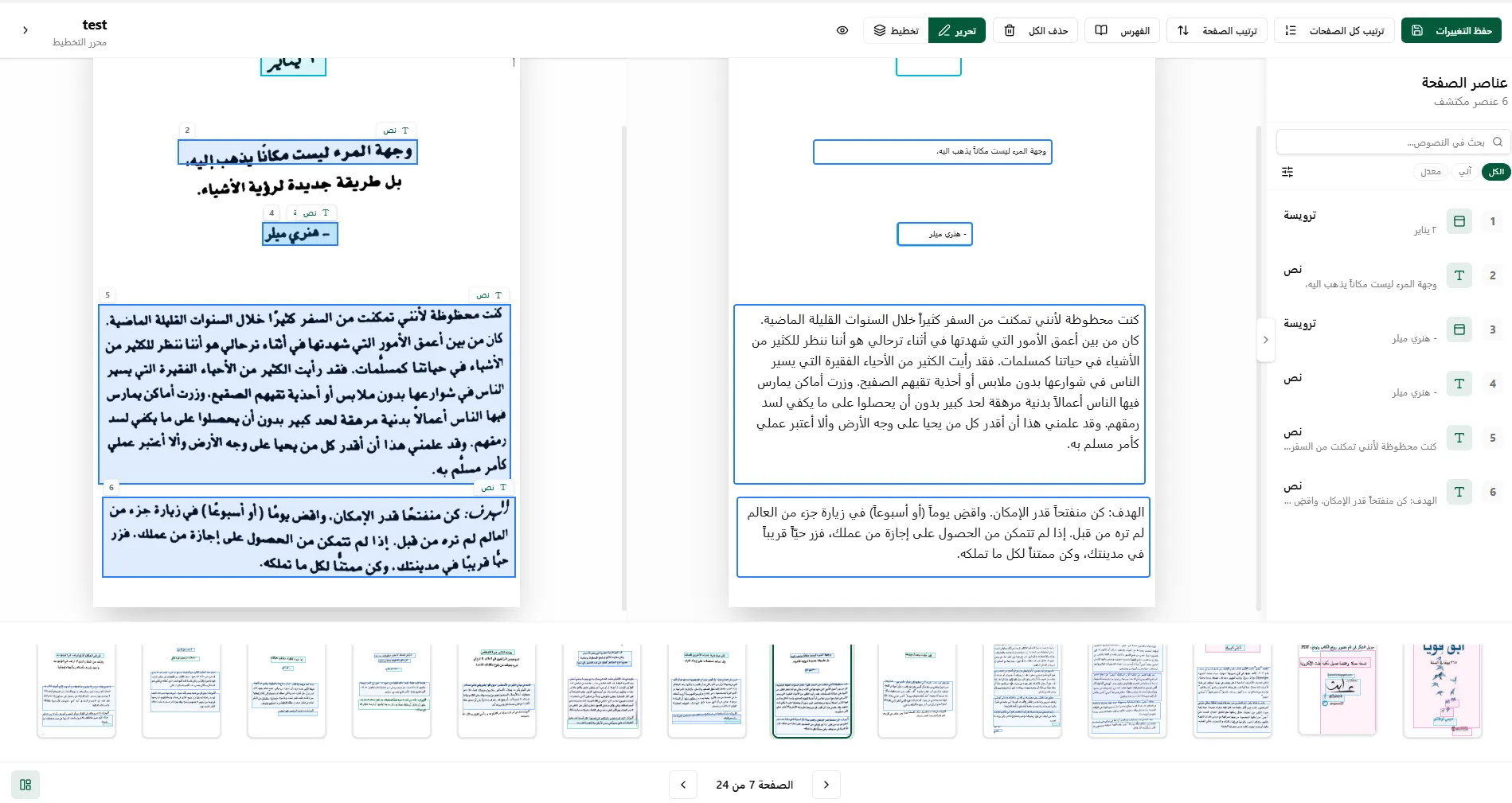
We can mirror the editing of detected boxes for simpler modifications.
Our editor streamlines the editing and text verification workflow, enhancing efficiency and accuracy in content management.
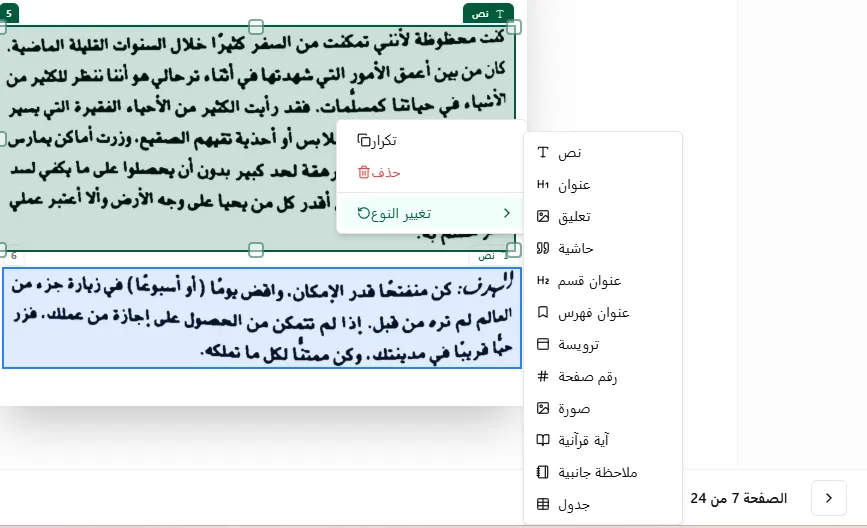
Comprehensive UI Control System for Box Management and Detection
This feature allows users to create, read, update, and delete (CRUD) items efficiently. Additionally, users can easily drag and drop items to reorganize them, as well as utilize undo and redo functionalities to manage their changes effectively.
Gallery

The Problem
Scanned book PDFs are often readable only as images, not as real digital books. Users cannot properly select text, search content reliably, adjust formatting, or reuse the material in accessible formats. This problem becomes even harder with scanned Arabic books, where complex layouts, right-to-left reading order, mixed content blocks, and OCR inaccuracies make digitization difficult. As a result, valuable books remain trapped in static scans instead of becoming searchable, editable, and readable digital content.